Improved Reporting and Debugging of Data Publishing

Anuar Ustayev
We've integrated our pipelines system with the website to display more insights to our users. Any dataset you publish on DataHub could be in one of three states: processing, succeeded or failed. Below we explain each state in detail.
Processing
While your dataset is being processed, you can see a dataset page with information about currently running steps. For instance, it might be creating a JSON version of your tabular data or validating it against a table schema:
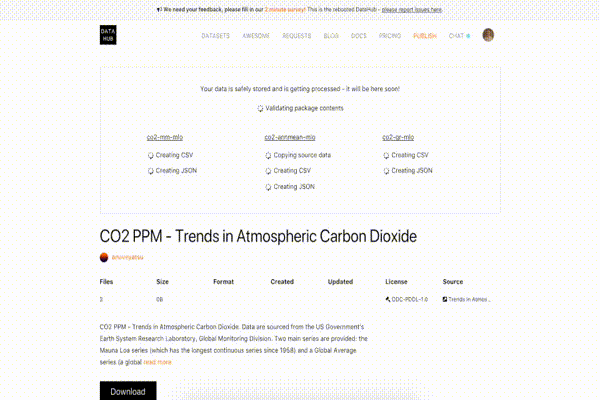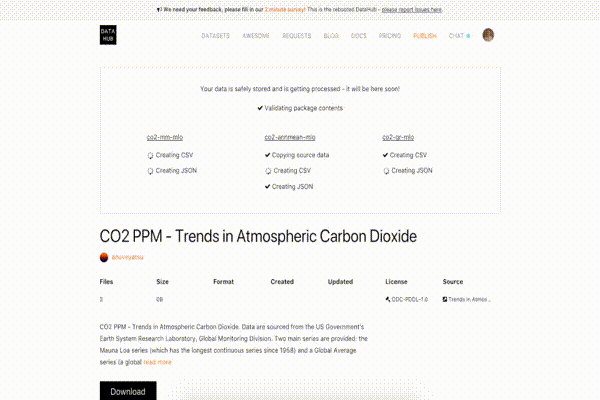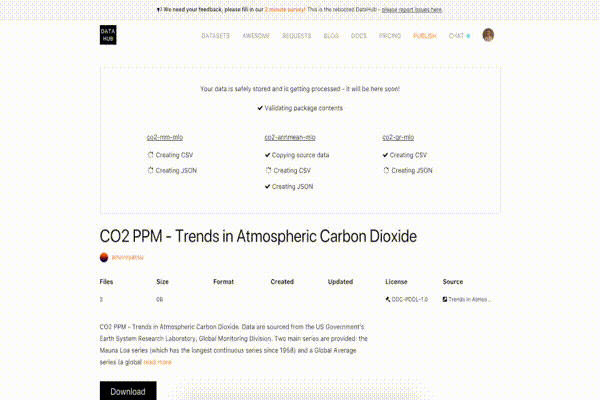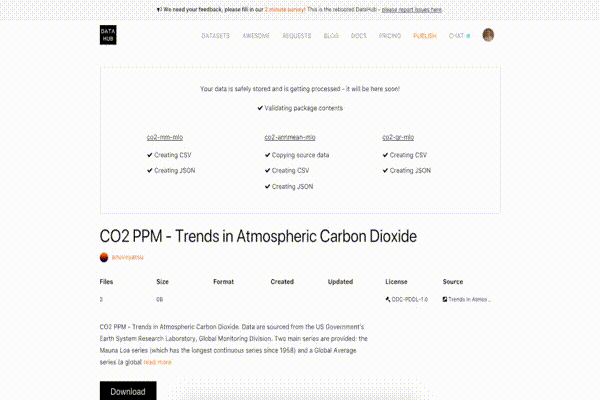
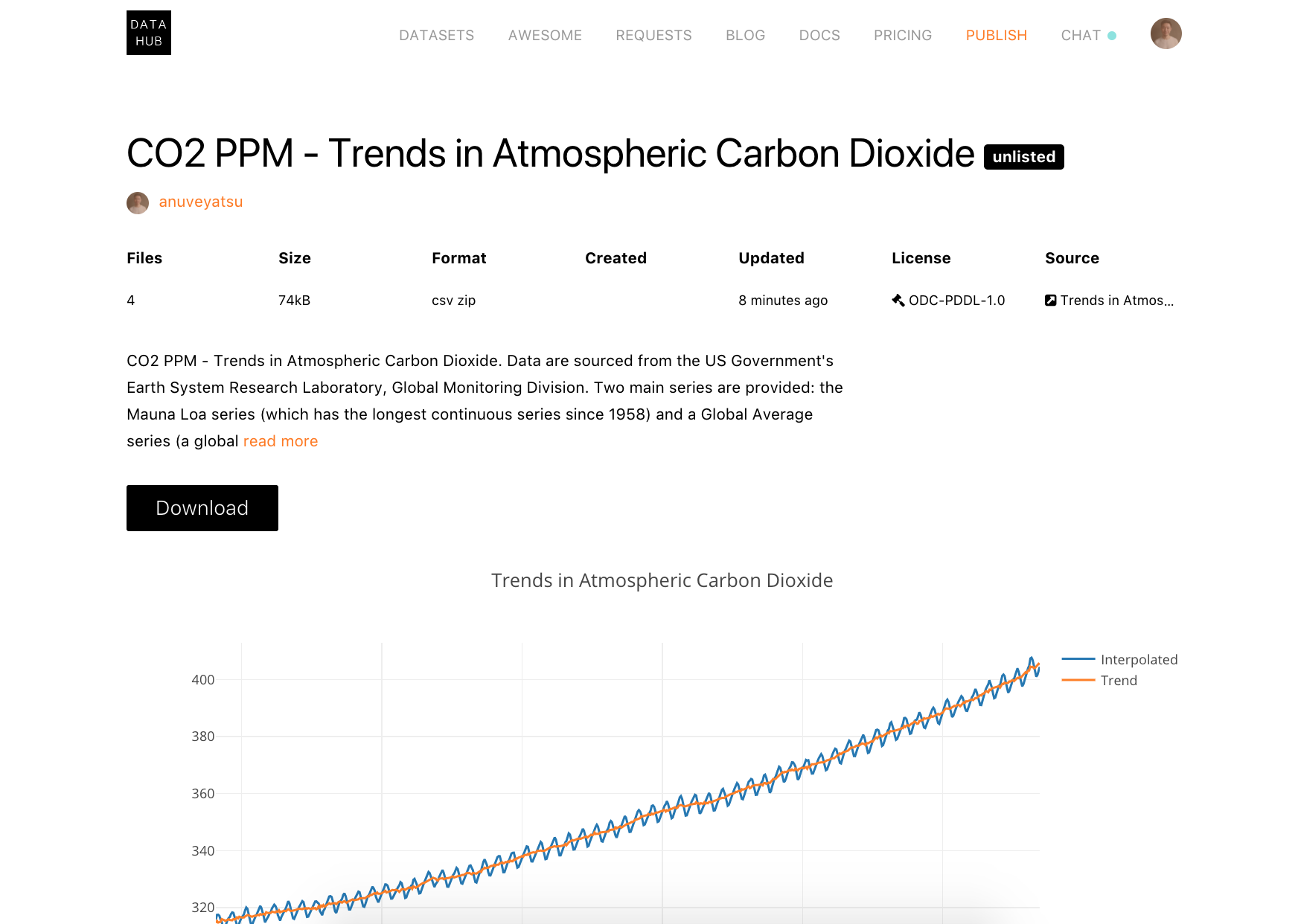
Succeeded
This is just a regular dataset page you have seen before:
Failed
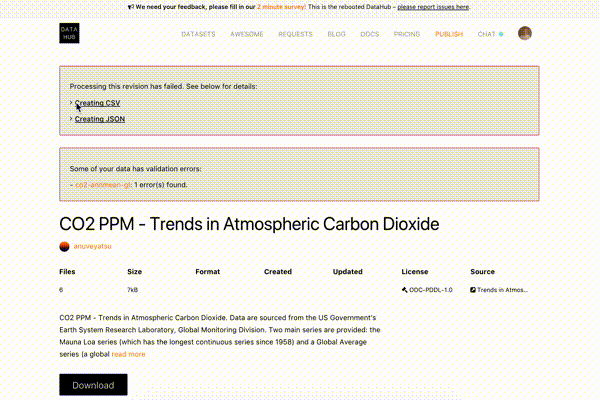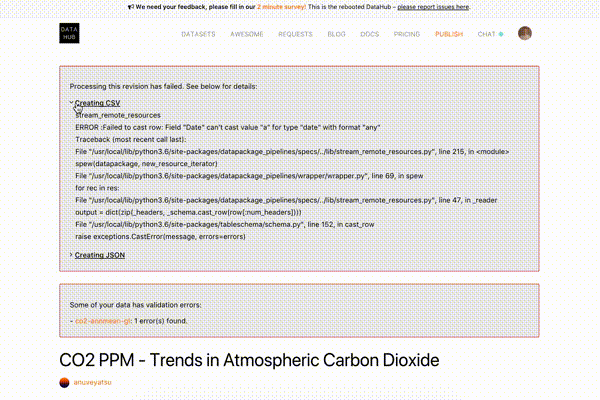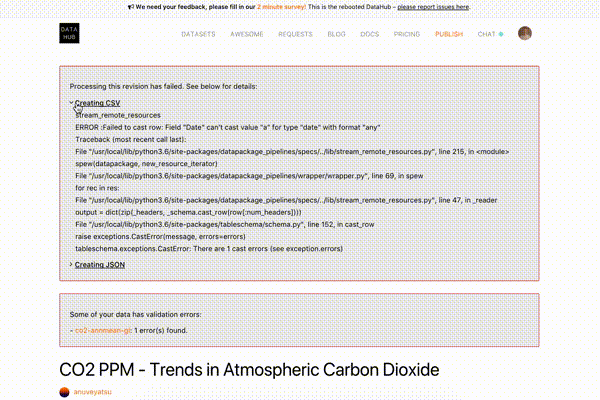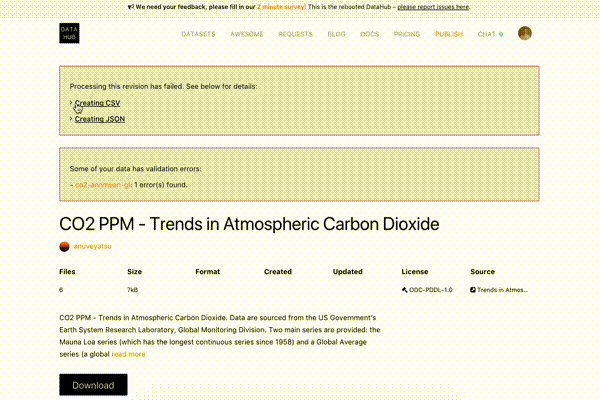
If processing a dataset has failed, you would see a notice about it with a pipeline title that caused the error. You can also expand the error to read the logs and find out the reason for the failure:
Different versions of your dataset
Each time you publish your dataset, a revision process is triggered for it. You can consider a revision as a version of your dataset, e.g., if it is the first time you have published a particular dataset, it would have version 1 (and the next revision would increment version by 1 so it'd be 2):
https://datahub.io/<username>/<dataset>/v/1
It becomes useful when you've re-published your dataset several times and you want to get your data in a specific stage.
:::info
A version is a natural number (integer larger than 0) and you can access the specific version of a dataset by /v/{number}.
:::